
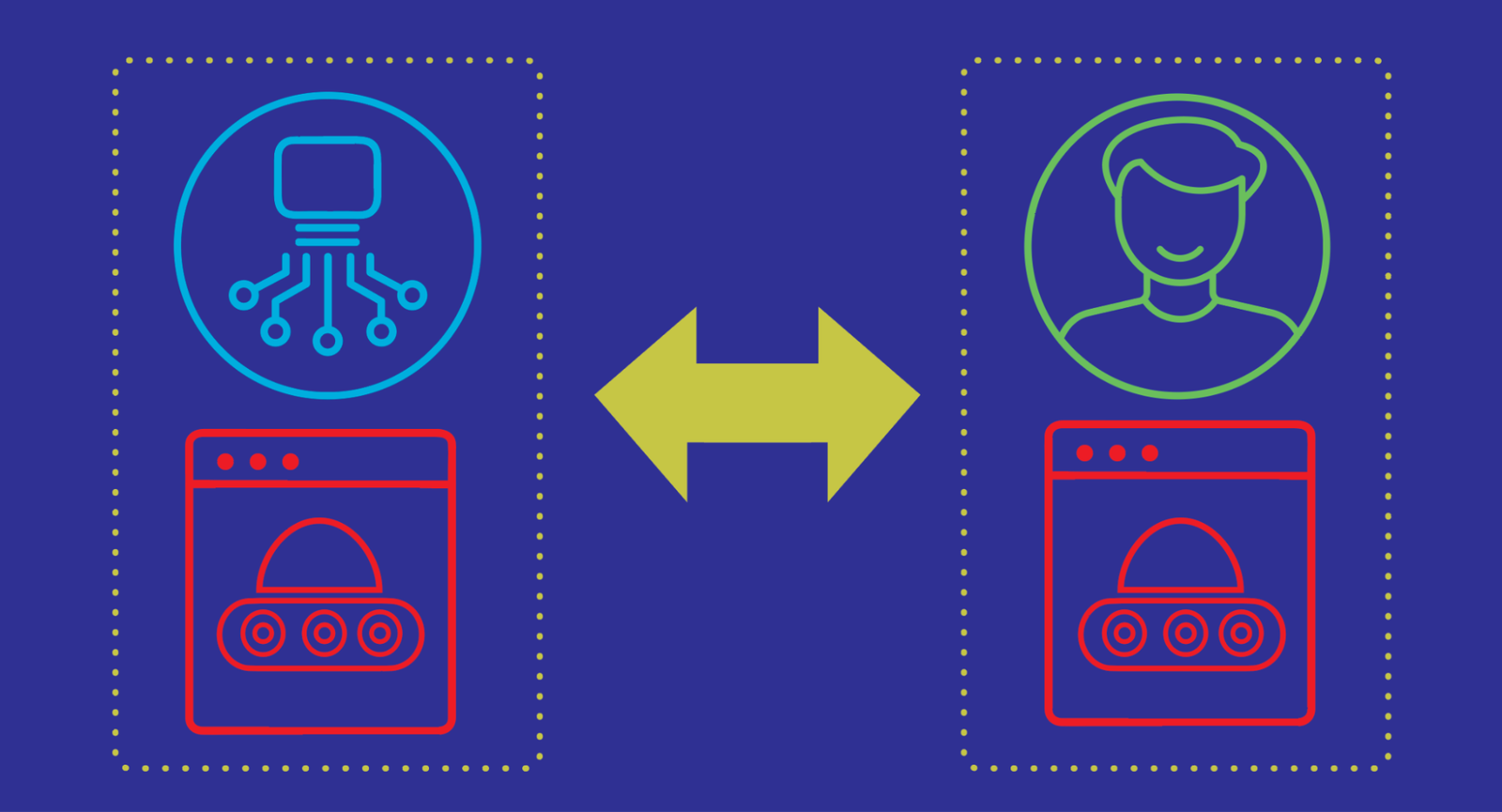
If you’ve ever tried to test a conversational AI agent with another LLM pretending to be a human, you’ve probably noticed something off. The simulated users are just too polite. They never get annoyed when the agent forgets their dietary restrictions for the third time, and somehow they know every obscure product detail without Googling anything. This is what the Google Research team calls the “realism gap,” and they’ve built a whole framework to measure and fix it.
Why this matters
Modern conversational agents can handle multi-turn tasks — asking clarifying questions, proactively helping, that sort of thing. But they fall apart in long interactions. They forget constraints, generate irrelevant responses, and generally frustrate real users. The gold standard for testing these systems is still live human testing, but that’s expensive, slow, and doesn’t scale. So the AI research community turned to LLM-based user simulators: agents instructed to roleplay as human users.
The problem is that most LLMs are trained to be helpful assistants. Asking them to play a frustrated, imperfect human is like asking a race car to drive like a minivan. It can do it, but not well. These simulators show atypical patience, unrealistic domain knowledge, and a weird verbosity that real humans don’t have. Think of it like a flight simulator where the weather is always perfect — you’re not training for the real world.
ConvApparel: the dataset and framework
ConvApparel is a new human-AI conversation dataset designed to expose these hidden flaws. The team collected conversations by randomly routing participants to either a helpful “Good” agent or an intentionally unhelpful “Bad” agent. This dual-agent setup captured the full spectrum of human behavior, from satisfaction to profound annoyance. The evaluation framework uses three pillars: population-level statistics, human-likeness scoring, and counterfactual validation.
The counterfactual validation part is the most interesting. It asks: how would a simulated user react if it encountered a frustrating system that looks nothing like the helpful ones it learned from during training? If the simulator just repeats training patterns, it’s useless for testing new, unproven agents. This is crucial because one primary goal of simulators is to help improve the agent, which often means experimenting with new policies that behave quite differently from the one used to generate the simulator’s training data.
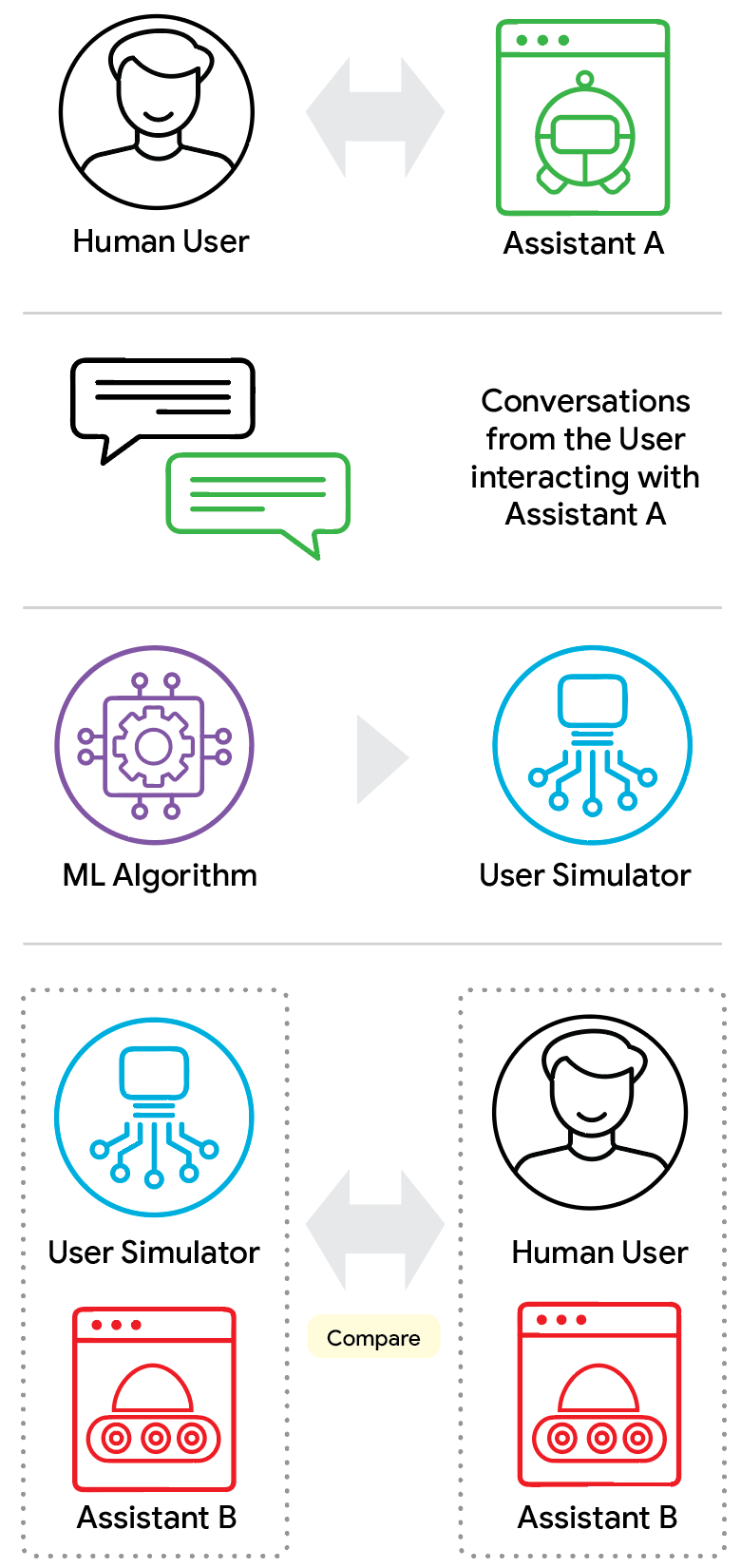
What they found
The paper focuses on Conversational Recommender Systems (CRSs), where an AI agent serves as a decision-support system. The team established a baseline for human behavior and then evaluated existing LLM-based simulators against it. The results weren’t pretty. Most simulators failed the counterfactual test — they couldn’t adapt to unexpected assistant behavior. They’d keep being polite even when the agent was clearly failing, or they’d suddenly display knowledge they shouldn’t have.
This is higher than I expected. I’ve worked with these simulators before, and I assumed the gap was smaller. But the data shows that even state-of-the-art LLMs struggle to roleplay as humans convincingly. The verbosity alone is a dead giveaway — real users don’t write three paragraphs when one sentence will do.
The path forward
ConvApparel isn’t just a dataset. It’s a framework for building better simulators. By quantifying the realism gap, the team provides a clear target for improvement. They suggest training simulators on adversarial examples — exposing them to bad agents during training so they learn to react realistically. This approach has been tried before in other domains, but applying it to user simulation is new.
I have one gripe: the paper is light on practical implementation details. How do you actually train a simulator to handle counterfactual scenarios? The framework tells you what to measure, but not how to fix it. Still, it’s a solid foundation. If you’re building conversational AI and relying on simulated users for testing, you need to read this paper. Your simulators are probably more unrealistic than you think.
Comments (0)
Login Log in to comment.
Be the first to comment!